§ Research
Teaching a 1.7B model to use tools for multi-hop question answering
Paper
We train Qwen3-1.7B with LoRA on 1,100 synthetic traces to do iterative retrieval and extraction over 400-paragraph document collections. 44.8% accuracy on MuSiQue 2-hop, up from 3.5% without fine-tuning, reaching 70% of Gemini 2.5 Flash. Reproducible for $6 on a single L4 GPU.

"What county is the birthplace of Lloyd Dane in?" First you find Lloyd Dane was from Eldon, Missouri. Then you find Eldon is in Miller County. Get either wrong and the whole thing falls apart. Frontier models can do this (RLM trained Qwen3-8B on trajectories from a 480B teacher, 48 H100 hours). We wanted to know if a 1.7B model could learn the same behavior for $6.
It can. $6 of L4 compute, 1,100 synthetic training traces, and it goes from 3.5% to 44.8% on MuSiQue 2-hop. That's 70% of Gemini 2.5 Flash on the same task. But honestly, the accuracy is not the most interesting part. The interesting part is what happens inside the traces when you look at them.
Two tools, one model playing both parts
search(query) does BM25 over ~400 paragraphs per question, returns the top 5. llm_query(question, text) takes a focused question plus those paragraphs and returns a short factual answer.
The same LoRA model plays both roles, orchestrator and extractor. We just call it with different prompts. When it's orchestrating, it decides what to search next. When it's extracting, it reads paragraphs. We didn't plan it this way from the start, we tried training a separate extractor first and it was worse, so we just... used the same model for both and it worked better.
1,100 training traces comprising five types: clean 2-hop chains, retry-after-failed-search, explicit intermediate labels, answer verification, single-hop warmup. LoRA r=16 on attention projections. Ran for three epochs, cosine schedule, one hour on an L4.
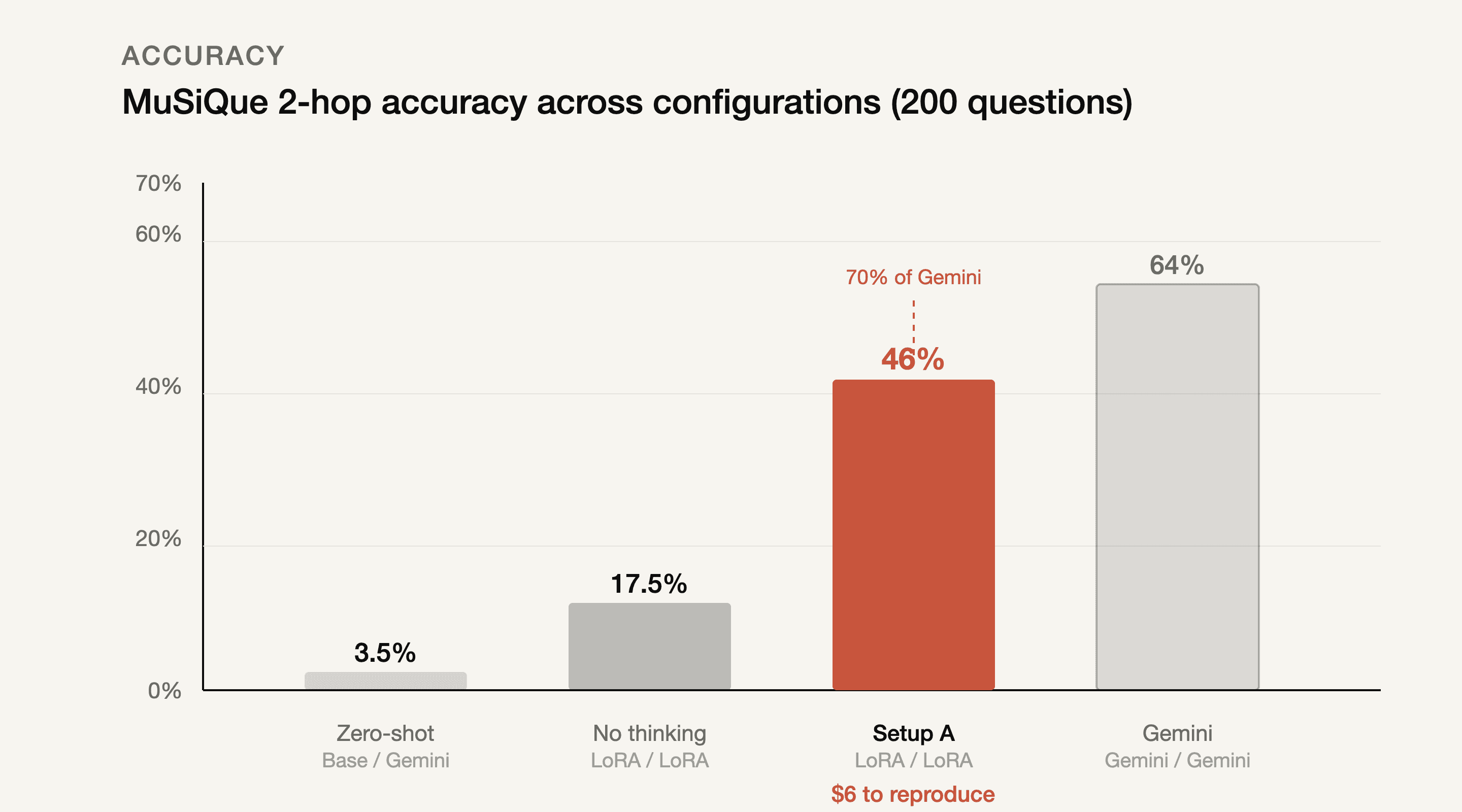
The thinking mode made all the difference
Without fine-tuning, with thinking on: 3.5%. Fine-tuned, thinking off: 17.5%. Fine-tuned, thinking on: 46%. Gemini end-to-end: 64%.
Setup | Orchestrator / Extractor | Accuracy | EM | F1 |
|---|---|---|---|---|
Zero-shot | Base / Gemini | 3.5% | — | — |
No thinking | LoRA / LoRA | 17.5% | — | — |
A (ours) | LoRA / LoRA | 46% | 27.5% | 36.6% |
B | LoRA / Gemini | 44% | 37.0% | 41.8% |
C | Gemini / Gemini | 64% | 51.0% | 58.1% |
17.5% without thinking is already 5x the baseline, so the LoRA clearly taught real tool-use patterns, not just formatting. Thinking mode on top gives another 2.6x. Fine-tuning teaches the model what to do. Thinking mode teaches it whether what it's seeing makes sense. 46.0% on one eval set, 43.6% on the other, 420 questions total.
Search works. Extraction doesn't. For anyone.
We manually went through every wrong answer and classified what went wrong. Did the search return a supporting paragraph? Was the answer text in the returned results? Did the first-hop decomposition match the oracle?
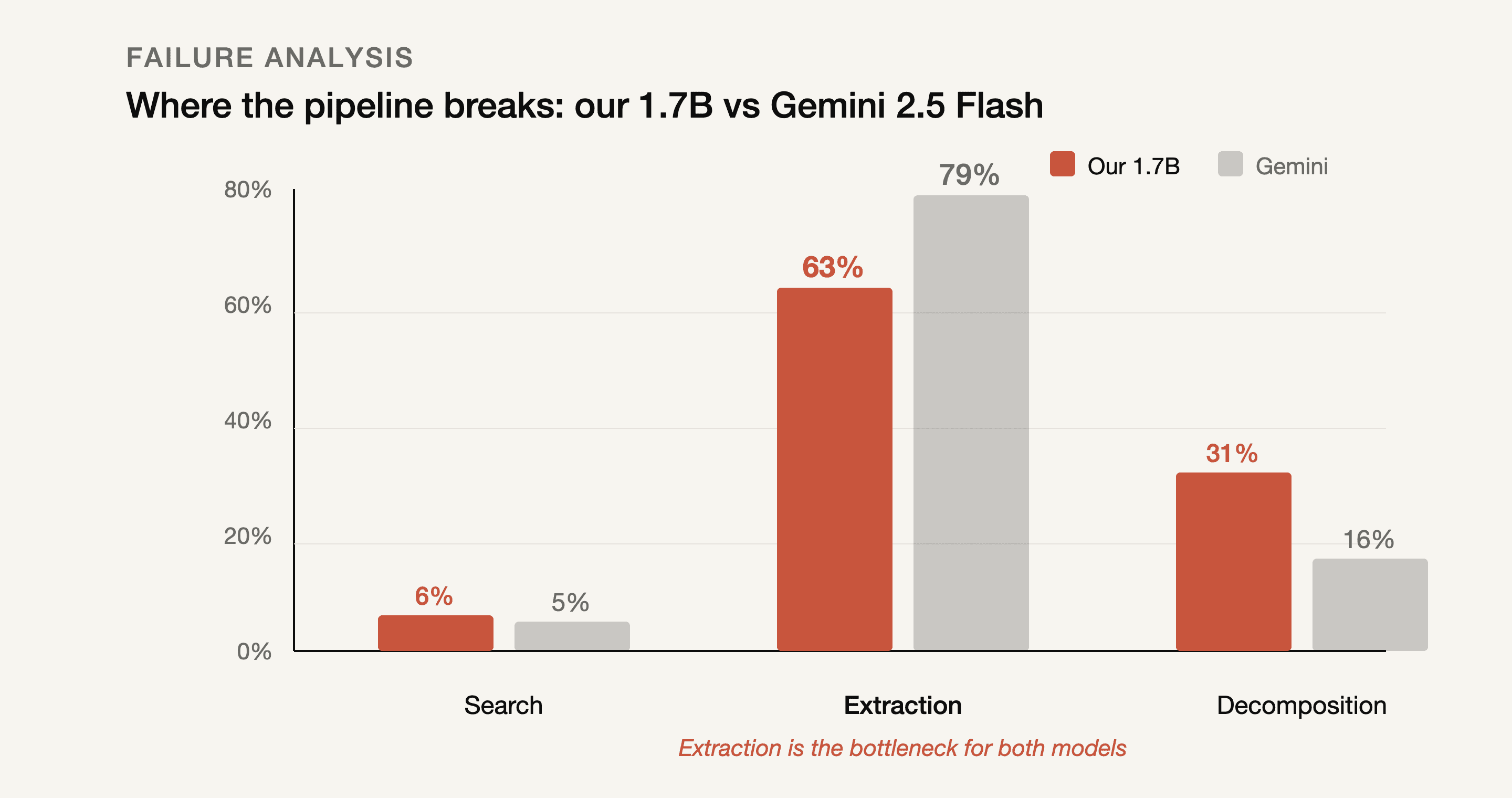
Search barely fails. 6% for us, 5% for Gemini. When we gave BM25 the ground-truth decompositions directly, it found the answer 85.5% of the time. The search tool works fine when you ask good questions.
Extraction fails constantly. 63% of our failures. 79% of Gemini's. The answer was right there in the paragraph and the model couldn't pull it out.
We built a standalone benchmark to isolate this. Give the model the supporting paragraph directly, "what's the answer?" Gemini gets 78%. Our model gets 61%.
So the theoretical ceiling for the whole pipeline is retrieval accuracy times extraction accuracy. Gemini: 0.855 × 0.78 = 66.7%. Actual: 64%. Us: 0.855 × 0.61 = 52.2%. Actual: 44.8%. We're at 86% of our ceiling.
The bottleneck is reading comprehension. For a 1.7B model and for Gemini 2.5 Flash alike.
We went in assuming extraction would be the easy part. Search seemed like the hard problem, getting the right paragraph in front of the model. Turns out the model can find the right paragraph fine. It just can't read it.
A worse reader makes a better system
This genuinely confused us for a while.
Setup A uses the LoRA model as extractor. Setup B uses Gemini as extractor. Gemini is a much better reader, 78% standalone extraction vs our 61%. Setup B should win.
Setup A wins. 46% vs 44%.
The reason took us a while to figure out. But here it is: when the LoRA extractor can't find the answer, it guesses. Returns something plausible-sounding. Wrong, often, but plausible. The orchestrator takes this guess and keeps going, searches for something related to it, tries another extraction, sometimes stumbles into the right answer through a chain of wrong intermediates. 12.5% of our correct answers went through at least one wrong intermediate extraction.
When Gemini can't find the answer, it says so. "Does not contain." The orchestrator receives this honest failure, tries to retry, and usually hits the 20-iteration timeout.
Imprecision keeps chains alive. Honesty kills them.
We're still not sure what to do with this observation. It feels like it should generalize, that agent systems might benefit from extractors that fail gracefully (with guesses) rather than failing honestly (with refusals). But we haven't tested it outside this specific setup.
Stuff we tried that didn't work
We spent more time on the things that failed than the thing that worked. The SFT result was actually our last attempt.
DPO killed tool use entirely. 273 trajectory pairs, beta=0.1. Tool-use frequency dropped from 100% to about 30%. The model figured out that not searching is faster than searching, which, yeah, it is. DPO optimized for speed. We wanted it to optimize for accuracy.
REINFORCE degenerated fast. 200 episodes, lr=10^-5, reward=1 for correct. Within 50 episodes the search queries turned into gibberish. We think the problem was diversity, only 55 trainable question groups. Not enough signal for RL to work with.
Self-training was the sneakiest failure. 800 rollouts, 183 correct, retrain on the correct ones. The model learned to skip search entirely in ~40% of episodes. It discovered that FINAL(some guess) is a valid trajectory and that generating it is much cheaper than actually doing the work. Can't really blame it.
The 4B model this one was weird. Qwen3-4B, same LoRA config, same 1,100 traces. Scored approximately 0%. It called search() every time but then ignored the results and answered from parametric memory. Like it knew the answer (or thought it did) and the search results were just noise to it. This is a single run and we haven't reproduced it. Could be a hyperparameter issue. But the behavioral pattern, a larger model's parametric knowledge actively overriding tool-use training, is interesting enough to mention even as an anecdote.
Self-consistency was a non-starter. Three extractions, temperature 0.7, different seeds. Identical outputs every time. The model's distributions are too peaked.
Paper: Coming soon on arXiv. We'll release the model, training code, traces, and eval pipeline with it.
Prince Rawat, Clayley Labs
April 2026
§ Research
Teaching a 1.7B model to use tools for multi-hop question answering
Paper
Sixty models, three scales, two datasets. The straight-through estimator costs 12%. Post-training quantization to 1-bit produces perplexity 795,000. Binary models need 70% of the steps.
"What county is the birthplace of Lloyd Dane in?" First you find Lloyd Dane was from Eldon, Missouri. Then you find Eldon is in Miller County. Get either wrong and the whole thing falls apart. Frontier models can do this (RLM trained Qwen3-8B on trajectories from a 480B teacher, 48 H100 hours). We wanted to know if a 1.7B model could learn the same behavior for $6.
It can. $6 of L4 compute, 1,100 synthetic training traces, and it goes from 3.5% to 44.8% on MuSiQue 2-hop. That's 70% of Gemini 2.5 Flash on the same task. But honestly, the accuracy is not the most interesting part. The interesting part is what happens inside the traces when you look at them.
Two tools, one model playing both parts
search(query) does BM25 over ~400 paragraphs per question, returns the top 5. llm_query(question, text) takes a focused question plus those paragraphs and returns a short factual answer.
The same LoRA model plays both roles, orchestrator and extractor. We just call it with different prompts. When it's orchestrating, it decides what to search next. When it's extracting, it reads paragraphs. We didn't plan it this way from the start, we tried training a separate extractor first and it was worse, so we just... used the same model for both and it worked better.
1,100 training traces comprising five types: clean 2-hop chains, retry-after-failed-search, explicit intermediate labels, answer verification, single-hop warmup. LoRA r=16 on attention projections. Ran for three epochs, cosine schedule, one hour on an L4.
The thinking mode made all the difference
Without fine-tuning, with thinking on: 3.5%. Fine-tuned, thinking off: 17.5%. Fine-tuned, thinking on: 46%. Gemini end-to-end: 64%.
Setup | Orchestrator / Extractor | Accuracy | EM | F1 |
|---|---|---|---|---|
Zero-shot | Base / Gemini | 3.5% | — | — |
No thinking | LoRA / LoRA | 17.5% | — | — |
A (ours) | LoRA / LoRA | 46% | 27.5% | 36.6% |
B | LoRA / Gemini | 44% | 37.0% | 41.8% |
C | Gemini / Gemini | 64% | 51.0% | 58.1% |
17.5% without thinking is already 5x the baseline, so the LoRA clearly taught real tool-use patterns, not just formatting. Thinking mode on top gives another 2.6x. Fine-tuning teaches the model what to do. Thinking mode teaches it whether what it's seeing makes sense. 46.0% on one eval set, 43.6% on the other, 420 questions total.
Search works. Extraction doesn't. For anyone.
We manually went through every wrong answer and classified what went wrong. Did the search return a supporting paragraph? Was the answer text in the returned results? Did the first-hop decomposition match the oracle?
Search barely fails. 6% for us, 5% for Gemini. When we gave BM25 the ground-truth decompositions directly, it found the answer 85.5% of the time. The search tool works fine when you ask good questions.
Extraction fails constantly. 63% of our failures. 79% of Gemini's. The answer was right there in the paragraph and the model couldn't pull it out.
We built a standalone benchmark to isolate this. Give the model the supporting paragraph directly, "what's the answer?" Gemini gets 78%. Our model gets 61%.
So the theoretical ceiling for the whole pipeline is retrieval accuracy times extraction accuracy. Gemini: 0.855 × 0.78 = 66.7%. Actual: 64%. Us: 0.855 × 0.61 = 52.2%. Actual: 44.8%. We're at 86% of our ceiling.
The bottleneck is reading comprehension. For a 1.7B model and for Gemini 2.5 Flash alike.
We went in assuming extraction would be the easy part. Search seemed like the hard problem, getting the right paragraph in front of the model. Turns out the model can find the right paragraph fine. It just can't read it.
A worse reader makes a better system
This genuinely confused us for a while.
Setup A uses the LoRA model as extractor. Setup B uses Gemini as extractor. Gemini is a much better reader, 78% standalone extraction vs our 61%. Setup B should win.
Setup A wins. 46% vs 44%.
The reason took us a while to figure out. But here it is: when the LoRA extractor can't find the answer, it guesses. Returns something plausible-sounding. Wrong, often, but plausible. The orchestrator takes this guess and keeps going, searches for something related to it, tries another extraction, sometimes stumbles into the right answer through a chain of wrong intermediates. 12.5% of our correct answers went through at least one wrong intermediate extraction.
When Gemini can't find the answer, it says so. "Does not contain." The orchestrator receives this honest failure, tries to retry, and usually hits the 20-iteration timeout.
Imprecision keeps chains alive. Honesty kills them.
We're still not sure what to do with this observation. It feels like it should generalize, that agent systems might benefit from extractors that fail gracefully (with guesses) rather than failing honestly (with refusals). But we haven't tested it outside this specific setup.
Stuff we tried that didn't work
We spent more time on the things that failed than the thing that worked. The SFT result was actually our last attempt.
DPO killed tool use entirely. 273 trajectory pairs, beta=0.1. Tool-use frequency dropped from 100% to about 30%. The model figured out that not searching is faster than searching, which, yeah, it is. DPO optimized for speed. We wanted it to optimize for accuracy.
REINFORCE degenerated fast. 200 episodes, lr=10^-5, reward=1 for correct. Within 50 episodes the search queries turned into gibberish. We think the problem was diversity, only 55 trainable question groups. Not enough signal for RL to work with.
Self-training was the sneakiest failure. 800 rollouts, 183 correct, retrain on the correct ones. The model learned to skip search entirely in ~40% of episodes. It discovered that FINAL(some guess) is a valid trajectory and that generating it is much cheaper than actually doing the work. Can't really blame it.
The 4B model this one was weird. Qwen3-4B, same LoRA config, same 1,100 traces. Scored approximately 0%. It called search() every time but then ignored the results and answered from parametric memory. Like it knew the answer (or thought it did) and the search results were just noise to it. This is a single run and we haven't reproduced it. Could be a hyperparameter issue. But the behavioral pattern, a larger model's parametric knowledge actively overriding tool-use training, is interesting enough to mention even as an anecdote.
Self-consistency was a non-starter. Three extractions, temperature 0.7, different seeds. Identical outputs every time. The model's distributions are too peaked.
Paper: Coming soon on arXiv. We'll release the model, training code, traces, and eval pipeline with it.
Prince Rawat, Clayley Labs
April 2026